W tym wpisie wprowadzam bardzo ważne rozróżnienie, które uwielbia się mylić wszystkim – od studentów po profesorów (tych mniej siedzących w statystyce). Czym innym jest rozkład zmiennej, a czym innym jest rozkład próbkowania. Co więcej, rozkłady próbkowania leżą u podstaw wnioskowania statystycznego, to koncept fundamentalny, więc warto je docenić. Są one podstawą wartości \(p\). To one (a nie rozkłady zmiennych!) powinny być normalne do analiz parametrycznych. Omawiam tutaj też błąd standardowy i Centralne Twierdzenie Graniczne.
Autor
Jakub Jędrusiak
Opublikowano
29 października 2023
Sięgnijmy pamięcią do przykładu z tekstu o wartości \(p\). Na tym tekście będziemy budować, więc zachęcam, żeby z nim zapoznać się w pierwszej kolejności. Konieczne jest też rozumienie podstaw rozkładu normalnego. Jeśli nie potrafisz obliczyć, powiedzmy, jaka część populacji ma inteligencję między 85 a 115, zachęcam do nadrobienia tekstu o rozkładach normalnych. Nie jest to niezbędne do zrozumienia większości tego tekstu, ale bardzo pomoże.
Sprawdzaliśmy tam między innymi kontrowersyjną (i fałszywą) hipotezę, że kobiety są mniej inteligentne od mężczyzn. Zbadaliśmy 100 kobiet i 100 mężczyzn i wyszło nam, że tak istotnie jest – mężczyźni osiągnęli średnią 101, kobiety 99. Wiedzeni nieufnością powtórzyliśmy nasze badanie i – ku naszemu zdumieniu – tym razem kobiety osiągnęły średnią 101 a mężczyźni 98. Po głębszym zastanowieniu możemy stwierdzić, że nie ma w tym nic dziwnego. W końcu całkowicie losowo mogę trafić na bardziej lub mniej inteligentną próbkę mężczyzn. Jakie jednak mogę mieć zaufanie do swoich wyników? Jak to, że moi mężczyźni osiągnęli średnią 98 ma się do rzeczywistej średniej wszystkich mężczyzn? Czy muszę zbadać ich wszystkich, żeby mieć pewność? To zgłębimy tutaj.
Cały sens statystyki polega na tym, żeby być w stanie pobrać próbkę i na jej podstawie powiedzieć coś na temat populacji, z której ją pobraliśmy (Wackerly, Mendenhall, & Scheaffer, 2008). Nie muszę więc badać wszystkich mężczyzn świata, żeby coś o nich (jako o zbiorowości) powiedzieć. Statystyka jest jednak lepsza od chłopskiego rozumu nie tylko w tym, że daje bardziej obiektywne dane, niż chłopski rozum (wbrew temu, co mogliśmy słyszeć od wujków przy rodzinnym stole), ale też pozwala powiedzieć, jak bardzo pewni możemy być naszych wniosków. Kluczowe pytanie na ten moment będzie więc brzmiało – skoro w mojej próbce 100 mężczyzn wyszła średnia 98, to jak to ma się do średniej inteligencji wszystkich mężczyzn?
1 Populacja i próba
Populacja to taka abstrakcja, oznaczająca mniej więcej „wszyscy”. Jeśli badamy żubry w Puszczy Białowieskiej, naszą populacją są żubry z Puszczy Białowieskiej. Jeśli interesują nas konkretnie biol-chemy z 3C, to nasza populacja to biol-chemy z 3C. Ale jeśli badamy biol-chemy z 3C, żeby powiedzieć coś o wszystkich biol-chemach w kraju, to po pierwsze nie mamy dobrej próbki, a po drugie naszą populacją stają się wszystkie biol-chemy w kraju. Populacją jest więc to, o czym chcemy wyciągać wnioski. Zbadanie całej populacji jest drogie, czasochłonne i często po prostu niepotrzebne. Zdarza się to, jak w odbywającym się co 10 lat spisie powszechnym, jednak możemy wyciągać sensowne wnioski na temat całych populacji na podstawie ich wycinków. Takie wycinki to próby.
Dobieranie próby do badań to jest całe duże zagadnienie w metodologii. Mówiąc jednak ogólnie, dobra próba powinna być po pierwsze liczna, a po drugie możliwie losowa.
Liczność próby to wymóg dość intuicyjny. Jak w starym kawale. Ja jestem biały, mój tato jest biały, moja mama jest biała, moja siostra jest biała, moi koledzy z klasy są biali, czyli nie ma czarnych ludzi. Tutaj również ujawnia się wyższość statystyki nad przemyśleniami wujka, który o stanie narodu z pozycji autorytetu wnioskuje na podstawie kolegów z wojska, a o stanie męskości na podstawie chłopaka w ciasnych spodniach, którego widział w supermarkecie. Może się to wydawać oczywiste, ale uznawana (choć powoli niknąca) psychoanaliza, olbrzymi system przekonań właściwie o wszystkim, co tkwi w człowieku, powstała na bazie sylwetek 38 pacjentów (Borch-Jacobsen, 2021). Związek liczności z pewnością wyrazimy tu matematycznie.
Próbka jest jednak dobra wtedy, kiedy jest losowa. Jeśli chcemy sprawdzić, ile książek rocznie czytają Polacy, to nie zaczaimy się z sondą uliczną pod biblioteką. Jeśli próbka jest rzeczywiście losowa, to nawet jeśli ktoś z tej próbki odstaje w jedną stronę, to prawdopodobnie ktoś inny odstaje podobnie w drugą stronę i ostatecznie się wyrównują. Pod warunkiem, że próba jest rozsądnie liczna.
2 Rozkład zmiennej w próbie
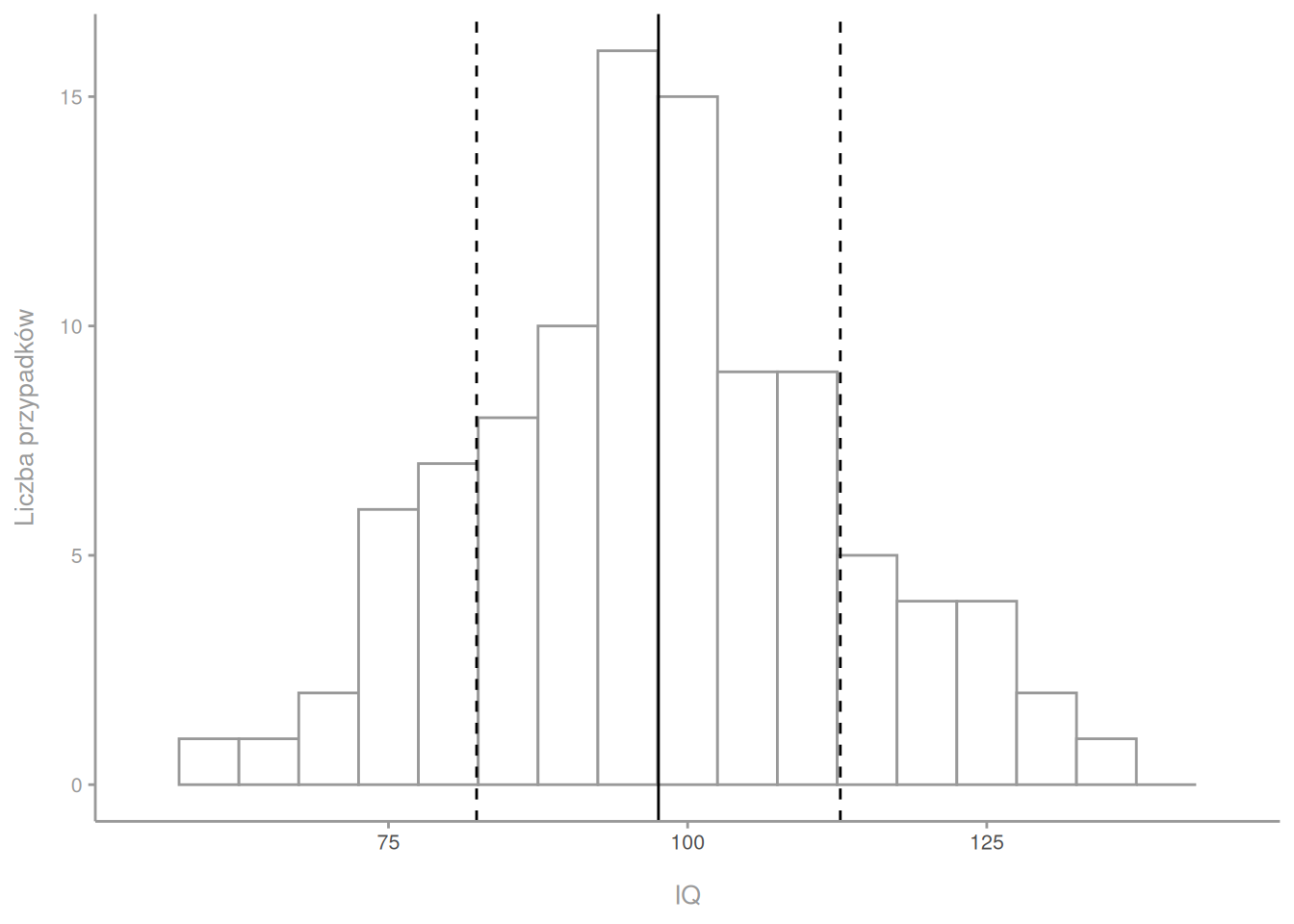
Załóżmy, że mamy losową próbę 100 mężczyzn i wszystkim mierzymy inteligencję. Niektórzy z tych mężczyzn mają współczynniki inteligencji 100, inni 95, jeszcze inni 105 itd. Wiedząc nieco o skali inteligencji nawet intuicyjnie będziemy czuć, że więcej ludzi będzie miało raczej przeciętną inteligencję, czyli około 100, niż 130 (co jest progiem przyjęcia do Mensy). Częstość poszczególnych wyników możemy przedstawić na histogramie (a potem dorzucić wykres gęstości, o czym mówiliśmy w tekście o gęstości prawdopodobieństwa).
Widzimy, że najwięcej osób wykazało inteligencję blisko środka rozkładu. Średnia inteligencja wyniosła w tej konkretnej próbie 97.6, co zaznaczyłem pionową kreską. To, co widzimy na rysunku, to rozkład zmiennej w próbie. Pobraliśmy próbkę, zmierzyliśmy inteligencję, narysowaliśmy rozkład. To, co widzimy na obrazku, odnosi się tylko do naszej konkretnej próby. Może przypominać rzeczywisty rozkład inteligencji w populacji (i przypomina), ale może to odwzorowanie może być dalekie od doskonałości. Istnieje więc jakiś rozkład zmiennej w populacji, który staramy się przybliżyć za pomocą rozkładu zmiennej w próbie. Im próba bardziej liczna, tym rozkład zmiennej bliższy prawdziwemu rozkładowi w populacji. Wydaje się to naturalne.
Poza średnią rozkład ma swoje odchylenie standardowe. Jest to podstawowe pojęcie, chociaż nieintuicyjne przy pierwszym kontakcie. W szczegółach omawiam je w tekście o wariancji, ale w uproszczeniu mówi nam ono o tym, gdzie znajduje się większość ludzi. Odchylenie standardowe w naszej próbie wyniosło 15.2, więc większość ludzi ma inteligencję między 82.4 a 112.8, czyli średnia ± odchylenie standardowe. Jeśli teraz usłyszymy, że ktoś w teście inteligencji uzyskał wynik 130, to możemy sobie pomyśleć „dużo, aż 2 odchylenia standardowe od średniej”. Tutaj zakres jednego odchylenia standardowego od średniej zaznaczyłem przerywanymi kreskami. Jeśli odchylenie standardowe jest niewielkie, to średnia ma nieduży błąd, pojedyncze obserwacje są blisko niej. Jeśli jest ono duże, możemy się spodziewać większego rozstrzału.
Losowanie osób do naszego badania możemy sobie wyobrazić jako losowanie z rozkładu zmiennej w populacji. Rozkład zmiennej w populacji mówi nam, jakie wyniki są częstsze, jakie rzadsze. Gdy wychodzimy na ulicę i pytamy ludzi, czy chcą wziąć udział w badaniu naukowym, mówiąc po statystycznemu losujemy z rozkładu. Osoba jest częścią populacji, więc losuję z rozkładu zmiennej w populacji. Rozkład budują ludzie. Gdy biorę losowego człowieka i mierzę jego inteligencję, statystyka każe nam patrzeć na to tak, jakbym wylosował wynik z rozkładu inteligencji w populacji. Powtarzam się, bo to naprawdę dziwne przejście z konkretnego, namacalnego zaczepiania ludzi na ulicy do matematycznej abstrakcji. Spróbuj oswoić się z tą perspektywą, nim przejdziesz dalej, bo przyda nam się w kolejnym podrozdziale.
3 Rozkład próbkowania
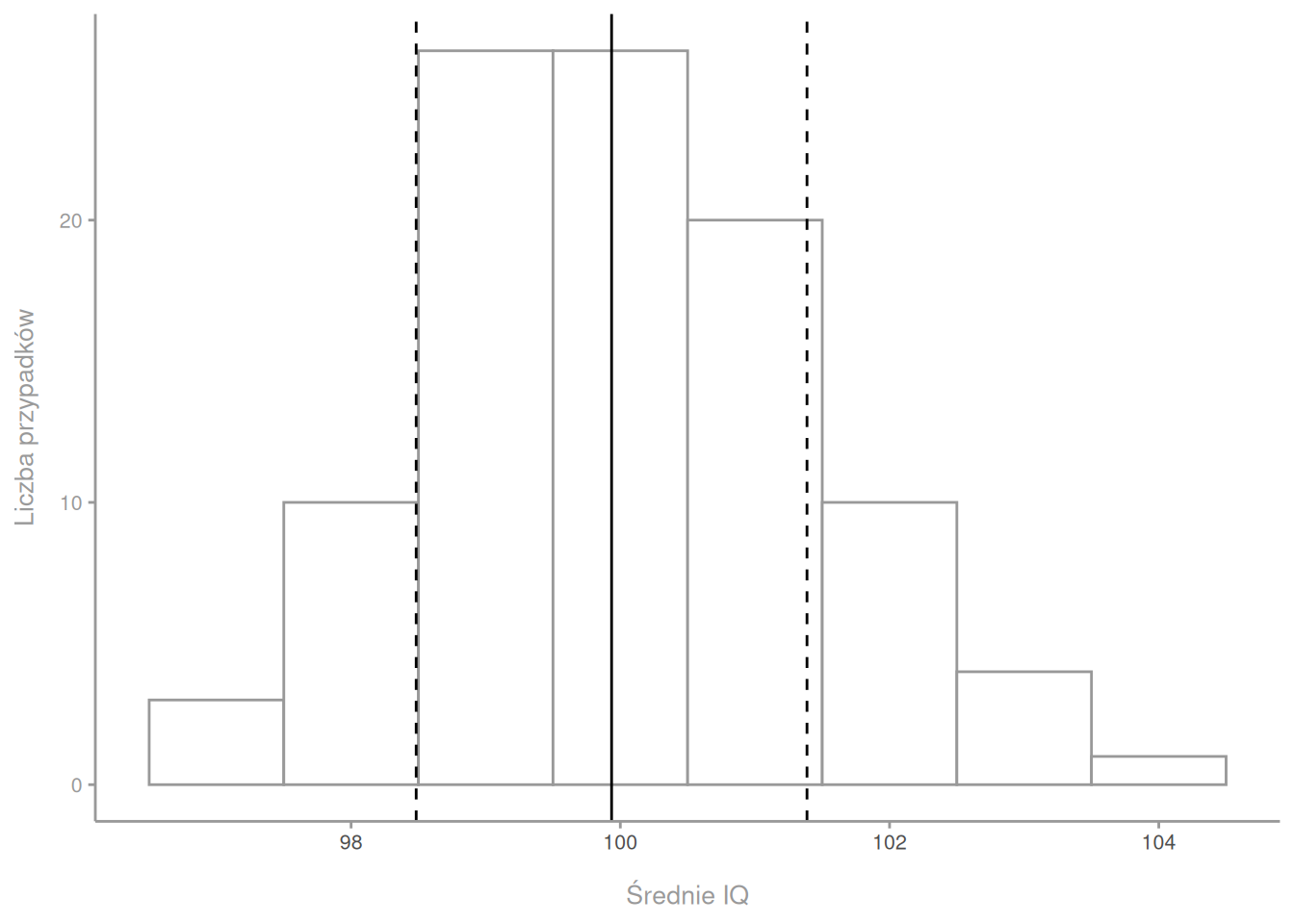
Wiemy jednak, że każda próbka może trochę różnić się średnią. W niektórych próbkach wyjdzie nam 102, w innych 98. Możemy jednak intuicyjnie czuć, że znacznie trudniej przez przypadek zebrać próbkę o średniej 130 albo 70. Raczej średnie każdej jednej próbki będą krążyć dookoła prawdziwej średniej, czyli w tym wypadku 100. Zazwyczaj nie wiemy, jaka jest prawdziwa średnia z populacji, ale jak sobie z tym poradzić powiemy później. Średnie bliżej 100 powinny pojawiać się częściej, a średnie dalej od 100 rzadziej, możemy więc zrobić 100 próbek, każda po 100 osób i zobaczyć, jak często losują nam się jakie średnie. Możemy to nanieść na histogram.
Wylosowaliśmy więc 100 różnych próbek, w każdej zmierzyliśmy średnią inteligencję. Na histogramie widać, że średnie w pobliżu 100 rzeczywiście pojawiały się częściej, niż te dalsze od 100. Średnia średnia wyniosła tutaj 99.9, zaś jej odchylenie standardowe 1.5, czyli zazwyczaj próbki miały średnią między 98.5 a 101.4. Zwróćmy jednak uwagę, że robiąc ten wykres, spłaszczyliśmy każdą próbkę 100 osób do jednej tylko liczby – średniej inteligencji. Ten wykres nie mówi nam więc nic na temat tego, jak wyglądał rozkład zmiennej w każdej próbce. On nam mówi tylko i aż tyle, jak często próbka 100 osób miała jaką średnią. Taki rozkład nazywamy rozkładem próbkowania. Rozkład próbkowania to rozkład średnich z różnych prób i jest czymś zupełnie innym niż rozkład zmiennej w próbie czy w populacji. I to rozróżnienie jest powalająco istotne.
Rozkład zmiennej w próbie przypomina rozkład zmiennej w populacji. Im więcej osób w próbie, tym bardziej. Rozkład próbkowania nie musi przypominać rozkładu zmiennej w populacji, ani się do niego nie zbliża. Rozkład zmiennej w próbie składa się z pojedynczych pomiarów, rozkład próbkowania składa się ze średnich. Rozkład zmiennej w próbie mówi nam, jak wiele osób w naszej próbce wpada w określone widełki. Rozkład próbkowania mówi nam o tym, jak łatwo wylosować próbkę o określonej średniej. Wykorzystajmy więc perspektywę, którą podpowiedziałem na koniec poprzedniego podrozdziału. Gdy losujemy osobę z ulicy i mierzymy jej inteligencję, to losujemy ją z rozkładu zmiennej w populacji. Gdy losujemy 100 osób z ulicy i liczymy ich średnią inteligencję, to losujemy średnią z rozkładu próbkowania. O średniej każdej próbki można myśleć jako o wylosowanej z rozkładu próbkowania, tak jak każda osoba ze swoją inteligencją jest wylosowana z rozkładu inteligencji w populacji.
Rozkładów próbkowania zazwyczaj się nie rysuje. Gdy pobieramy próbę, mamy tylko jedną średnią, nie ma sensu robić histogramu z jednej liczby. Rozkład próbkowania to pewna abstrakcja. Tak jak można sobie teoretycznie wyobrazić, że zbadaliśmy wszystkich członków populacji, by uzyskać rozkład zmiennej, tak możemy sobie wyobrazić, że zbadaliśmy wszystkie możliwe próbki po 100 osób, by uzyskać rozkład próbkowania. Dlaczego to jest istotne? Bo mówi nam, jak wiele zaufania możemy mieć do pojedynczej średniej z próby. W jaki sposób?
Załóżmy, że rozkład próbkowania ma średnią 100 i odchylenie standardowe 5. Odchylenie standardowe rozkładu próbkowania to coś zupełnie innego niż odchylenie standardowe rozkładu zmiennej! Odchylenie standardowe rozkładu inteligencji wynosi 15, ale rozkład próbkowania nie mówi nam o inteligencji pojedynczych ludzi, tylko o średniej inteligencji grup ludzi. To są dwa różne odchylenia! Za to średnia rozkładu próbkowania jest równa średniej z populacji. Wracając. Jeśli średnia rozkładu próbkowania wynosi 100, a odchylenie standardowe 5, to nagminnie powinniśmy się spodziewać średnich między 95 a 105. Średnia 115 powinna nas zdziwić znacznie bardziej. Jeśli w takim wypadku wyszłoby nam, że w naszej próbce kobiety mają inteligencję 100, a mężczyźni 115, to bylibyśmy bardziej skłonni stwierdzić, że coś jest na rzeczy. Intuicyjnie możemy też czuć, że średnie 100 i 102 nie zrobiłyby na nas takiego wrażenia, bo naprawdę łatwo uzyskać je przez przypadek, bo większość średnich będzie między 95 a 105.
4 Centralne Twierdzenie Graniczne
Teraz się zacznie robić ciekawie. Trzymaj się, już za niedługo będą przykłady. Do tej pory rozkład próbkowania był tylko abstrakcją. Czymś, co równie trudno zmierzyć, jak prawdziwą średnią z populacji. Na co dzień myślę dość konkretnie, abstrakcje są mi potrzebne wtedy, gdy mogę je wykorzystać do myślenia czy w innym celu. Po co mi więc taka abstrakcja jak rozkład próbkowania? Bo mając pojedynczą próbkę, jej średnią i odchylenie standardowe, wbrew pozorom, można całkiem sporo powiedzieć o rozkładzie próbkowania, z którego ta średnia pochodzi. Pozwala nam na to przepotężne prawo, leżące u podstaw całej statystyki, zwane Centralnym Twierdzeniem Granicznym (Central Limit Theorem).
4.1 Normalność
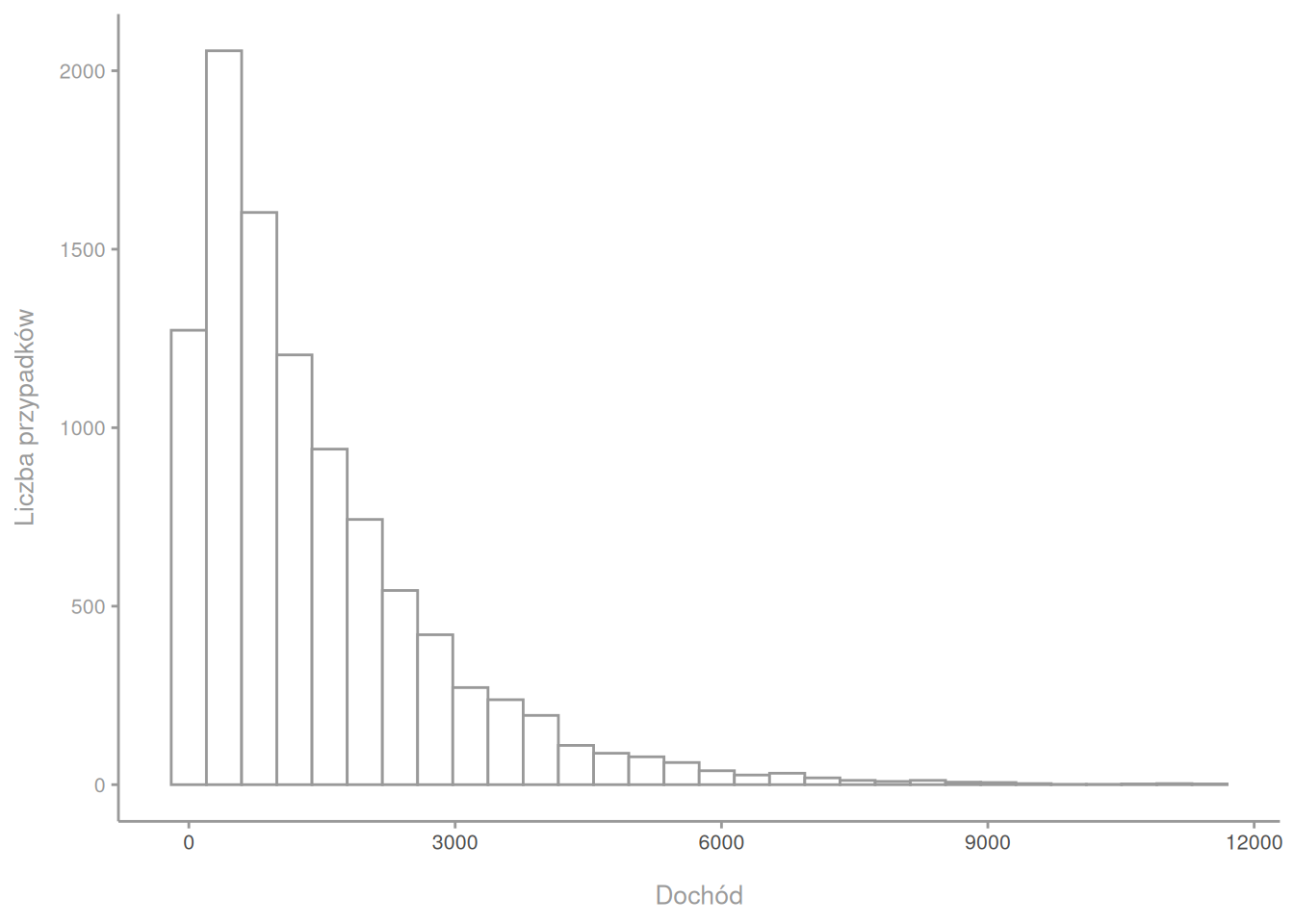
Twierdzenie to mówi nam o dwóch piekielnie ważnych rzeczach. Po pierwsze, jeśli próba jest odpowiednio duża1, to każdy rozkład próbkowania jest normalny. Odpowiednio duża oznacza tutaj według większości autorów minimum 15 osób, chociaż co bardziej konserwatywni autorzy mówią 20 albo nawet 30 osób. Podkreślam tutaj słowo każdy. Oznacza to, że nieważne, jak wygląda rozkład zmiennej, czy jest normalny, czy nie. Rozkład próbkowania będzie normalny. Wyobraźmy sobie, że rozkład poniżej to rozkład zarobków w pewnym państwie. Większość ludzi zarabia niedużo, ale jest też niewielka ilość ludzi zarabiająca bardzo dużo.
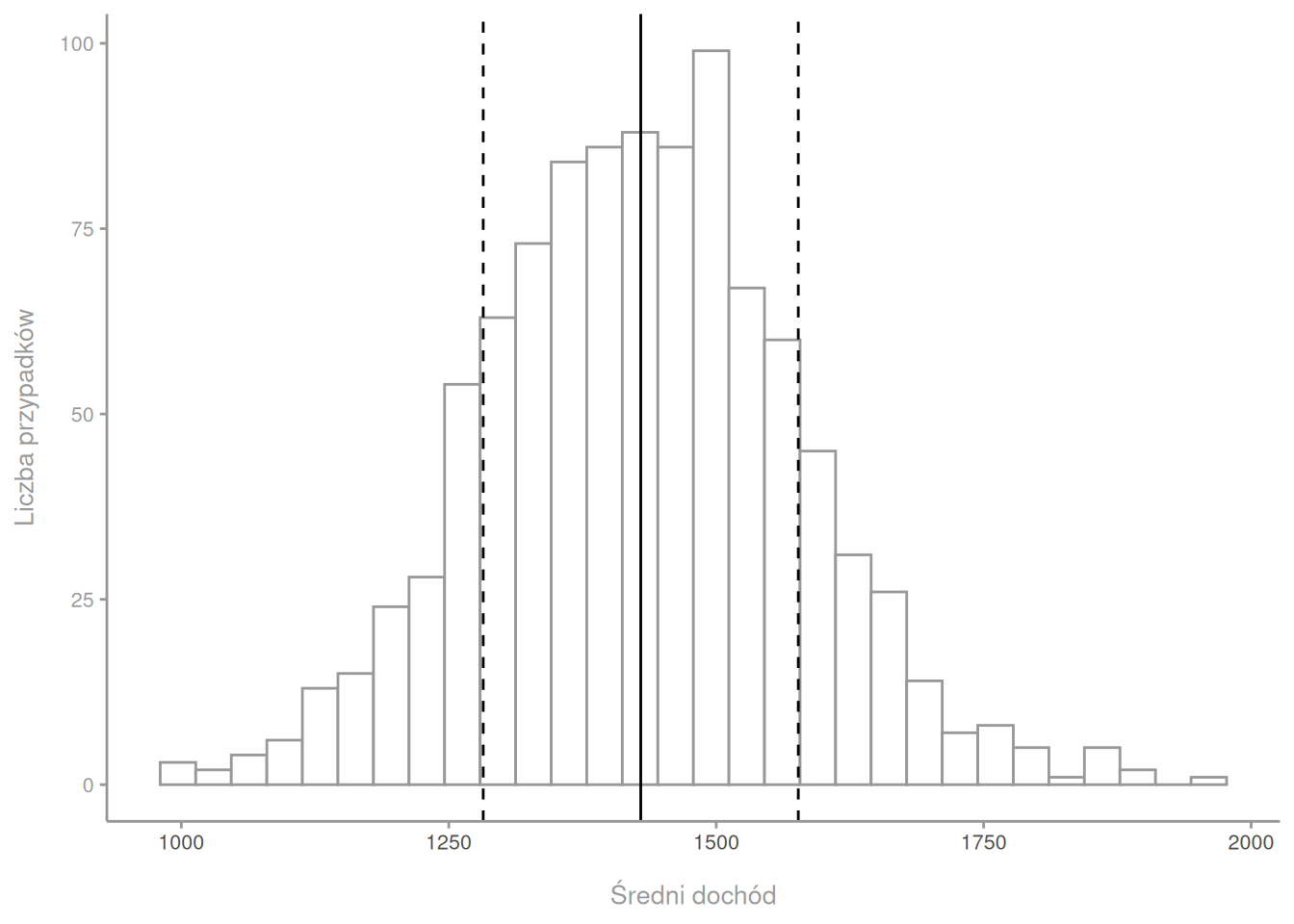
Z pobieram z tego rozkładu losową próbkę 100 osób. Wychodzi mi średni dochód 1185. Spoko. Pobieram kolejne 100 osób i tym razem dostaję średni dochód 1448. Robię tak jeszcze bardzo dużo razy, więc ostatecznie mam zapisane w Excelu bardzo dużo średnich. Gdy z tych średnich, nie z pojedynczych obserwacji, zrobię histogram, dostanę coś takiego.
Ten rozkład wygląda zupełnie inaczej, niż rozkład wyjściowy. Dlaczego? Bo rozkład wyjściowy to rozkład zmiennej, a to na obrazku to rozkład średnich, jakie wychodzą w różnych próbkach, czyli rozkład próbkowania. Wielkość pojedynczej próbki wynosi 100, czyli więcej niż 15, a więc rozkład próbkowania wyszedł normalny. To jest pierwsze, co mówi nam CLT.
Jest to założenie o tyle ważne, że idzie na przekór popularnym w naukowym świecie nieporozumieniom. W części testów (np. w teście \(t\)) istnieje założenie o normalności. Ta normalność dotyczy jednak nie rozkładu zmiennej, ale rozkładu próbkowania. Dane wcale nie muszą rozkładać się normalnie! Jeśli mamy te minimum 15-30 osób, to rozkład próbkowania i tak jest normalny na mocy centralnego twierdzenia granicznego. Owszem, możemy sprawdzić, czy dane rozkładają się normalnie, bo jeśli tak, to rozkład próbkowania też jest normalny, ale nawet najbardziej szalone rozkłady zmiennej mają normalne rozkłady próbkowania, o ile liczność próbki jest wystarczająca.
Jeśli czytałeś(-aś) tekst o rozkładach normalnych, możesz się już domyślać, dlaczego to jest ważne. Jeśli wiemy, że rozkład jest normalny, to moglibyśmy powiedzieć, np. „OK, w mojej próbce dzieci karmionych kalarepą średnia inteligencja wynosi wynosi 110. Rozkład próbkowania ma średnią 100 i odchylenie standardowe 5, więc szansa na to, że taka lub wyższa średnia wylosuje się z rozkładu normalnego przez przypadek wynosi \(\int_{110}^{\infty} \mathcal N(x;\ 100,\ 5^2) = 1 - pnorm(110,\ mean = 100,\ sd = 5) \approx 2,3\%\), a więc raczej nie jest to przypadek”. Skąd jednak mam wiedzieć, jaką średnią i odchylenie standardowe ma rozkład próbkowania, jak mam tylko jedną próbkę?
WskazówkaZadanie
Szybka powtórka z rozkładów normalnych i rozgrzewka w myśleniu o rozkładach próbkowania.
Twoja próbka 40 osób ma średnią 121. Rozkład próbkowania ma średnią 100 i odchylenie standardowe 7. Jaka jest szansa, że próbka 40 osób będzie miała średnią 121 lub wyższą?
Twoja próbka 120 osób ma średnią -0,78. Rozkład próbkowania ma średnią 0 i odchylenie standardowe 0,5. Jaka jest szansa, że próbka 120 osób będzie miała średnią taką lub niższą?
Twoja próbka 300 osób ma średnią 5,7. Rozkład próbkowania ma średnią 5,5 i odchylenie standardowe 0,65. Różnica między Twoją średnią a średnią rozkładu próbkowania wynosi 0,2. Jaka jest szansa wylosowania próbki o takim lub większym odchyleniu (czyli mniej niż 5,3 lub więcej niż 5,7)?
Druga rzecz, na którą pozwala nam CLT to dokładnie rozwiązanie naszego problemu. Mówi nam ono, że możemy oszacować odchylenie standardowe rozkładu próbkowania dzieląc odchylenie standardowe naszej próbki przez pierwiastek z liczby osób badanych.
\[
SE = \frac{SD}{\sqrt{N}}
\]
Rozszyfrujmy to sobie i podajmy przykład. Skrót \(SE\) oznacza błąd standardowy. Jest to specjalna nazwa na odchylenie standardowe rozkładu próbkowania. Pozwala ona odróżnić łatwo odchylenie standardowe rozkładu zmiennej, od odchylenia standardowego rozkładu próbkowania. \(N\) to liczba osób w próbce. \(SD\) w tym wzorze odnosi się do odchylenia standardowego zmiennej. Jeśli znamy prawdziwe odchylenie standardowe w populacji, to możemy je wykorzystać, ale jeśli nie (czyli zazwyczaj), to możemy je zastąpić odchyleniem standardowym naszej próbki. Jeśli sięgniesz pamięcią do wzoru na odchylenie standardowe, to możesz sobie przypomnieć, że sumę odchyleń podniesionych do kwadratu dzieliliśmy przez \(N - 1\) zamiast przez \(N\). Jest to takie zabezpieczenie wbudowane we wzór na odchylenie standardowe, dzięki któremu odchylenie standardowe z próby bardziej przypomina to z populacji. Dzięki temu, że dzieliliśmy przez \(N - 1\) zamiast przez \(N\), teraz możemy podstawiać do wzoru na błąd standardowy odchylenie standardowe z próby.
Zaczęliśmy od wylosowania próbki 100 mężczyzn i zmierzeniu ich inteligencji. Wiemy, że rozkład inteligencji ma średnią 100, a więc rozkład próbkowania również ma średnią 100. Odchylenie standardowe wynosi 15, co również wiemy dlatego, że wiemy odrobinę o inteligencji. Możemy więc oszacować błąd standardowy, czyli odchylenie standardowe rozkładu próbkowania.
\[
SE = \frac{SD}{\sqrt{N}} = \frac{15}{\sqrt{100}} = 1,5
\]
Przypomnijmy, że wcześniej zrobiliśmy symulację rozkładu próbkowania, losując 100 próbek po 100 osób i licząc średnie. Tak uzyskany rozkład próbkowania miał odchylenie standardowe 1.45. Jak widzimy, było to w miarę rozsądne oszacowanie, ale jeśli zamiast 100 próbek pobralibyśmy 1000, 10 000 czy 100 000, to nasz symulowany rozkład miałby odchylenie standardowe coraz bliższe 1,5. Poniżej przedstawiam 3 wykresy gęstości, które pokazują, że im więcej próbek włączymy do symulacji, tym rozkład staje się bardziej normalny, a jego odchylenie standardowe bliższe prawdziwemu. Oznacza to, że symulacja symulacją, ale pod spodem czai się jakiś prawdziwy rozkład próbkowania, który ma średnią 100 (równą prawdziwej średniej z populacji) i odchylenie standardowe 1,5.
W naszym drugim przykładzie z dochodami nie znamy prawdziwego odchylenia standardowego, ale możemy je oszacować. Załóżmy, że wylosowałem 100 osób, zapytałem o dochody i wyszło mi odchylenie standardowe 1753,93. Możemy oszacować błąd standardowy:
\[
SE = \frac{1753,93}{\sqrt{100}} \approx 175
\]
Jeśli wiedziałbym, że prawdziwa średnia wynosi, powiedzmy 1600 (ze średnią poradzimy sobie potem), to próbki ze średnią między 1425 i 1775 mogę uznać za zupełnie typowe (ok. 67% przypadków według prawa trzech sigm), zaś próbki ze średnią między 1250 a 1950 za zupełnie typowe (ok. 95% przypadków według prawa trzech sigm). Jeśli dzieci karmione kalarepą osiągałyby średni dochód na poziomie 2000, to miałbym mniej niż 5% szans, że ten wynik jest przypadkowy.
Z tego wzoru wynika też ważny wniosek – im większa próbka, tym mniejszy błąd standardowy. Możemy to sobie przedstawić na wykresach. Poniżej nałożyłem na siebie 3 histogramy. Każdy histogram to
95% próbek 100 osób będzie miało średnią inteligencję między 97 a 103 (\(100 \pm 2 \times 1,5\)), co policzyliśmy wyżej. Różnica między 100 a 101 będzie więc typowa, bo bardzo łatwo uzyskać ją przez przypadek. Jeśli jednak nasza próbka wyniesie nie 100, a 1000 osób, to błąd standardowy spadnie do \(SE = \frac{15}{\sqrt{1000}} \approx 0,47\), a więc 95% próbek będzie miało średnią między 99,06 a 100,94. Tym samym średnia 101 staje się bardziej podejrzana. Ba! Staje się istotnie różna od 100, bo szansa na uzyskanie jej przez przypadek w próbie 1000 osób jest mniejsza niż 5%2. Takie widełki nazywamy 95% przedziałem ufności. Jeśli chcemy uzyskać dokładnie 95% pewności, będziemy mnożyć błąd standardowy nie przez 2, jak zrobiłem to wyżej, a przez 1,96 (patrz odwrotna dystrybuanta rozkładu normalnego).
WskazówkaZadanie
Pewna zmienna ma rozkład o średniej 5,5. 25 dzieci karmionych kalarepą uzyskuje średnią 5,8 z odchyleniem standardowym 0,5. Jaka jest szansa, że wynik jest przypadkowy? Załóż hipotezę prawostronną (tj. że średnia u dzieci jest 5,8 albo wyższa). Oblicz 95% przedział ufności dla średniej 5,5.
AdnotacjaOdpowiedź
4.2.1 Błąd standardowy
\[
SE = \frac{0,5}{\sqrt{25}} = \frac{0,5}{5} = 0,1
\]
Centralne Twierdzenie Graniczne pozwala nam sobie wyobrazić rozkład możliwych średnich, jakie da nam próbka o określonej wielkości. Co więcej, pozwala liczyć prawdopodobieństwo. Załóżmy, że mam próbkę o odchyleniu standardowym 20 i średniej 10. Próbka liczyła 100 osób, więc błąd standardowy wynosi \(SE = 20 \divsymbol \sqrt{100} = 2\). Oznacza to, że np. średnią 12 lub większą wylosuję z prawdopodobieństwem \(\int^\infty_{12} \mathcal{N}(x;\ 10,\ 2^2) dx \approx 15,87\%\). Jeśli jednak moja próbka będzie miała 1000 osób (i takie samo odchylenie standardowe i średnią), to mój błąd standardowy wyniesie już \(SE = 20 \divsymbol \sqrt{1000} \approx 0,63\). W tym momencie szansa na wylosowanie próbki o średniej 12 lub więcej spada praktycznie do zera (zachęcam do policzenia). Pojawia się jednak pewien problem. Cicho założyłem tutaj, że średnia 10 naprawdę jest średnią z populacji. Ale w rzeczywistości przecież nie musi tak być! Średnia z mojej konkretnej próbki przecież jest obarczona losowym błędem. Może być wyższa od prawdziwej albo niższa od prawdziwej. Skąd ja mam to wiedzieć? A jeśli nie znam prawdziwej średniej, to czy rzeczywiście mogę powiedzieć cokolwiek o rozkładzie próbkowania, skoro średnia rozkładu próbkowania jest równa średniej z populacji? Jest na to metoda.
Przypomnijmy sobie, że (jeśli próbka jest odpowiednio duża) rozkład próbkowania jest normalny. Rozkłady normalne opisują dwie liczby – średnia i odchylenie standardowe. Odchylenie standardowe rozkładu próbkowania to błąd standardowy i, jak już mówiliśmy, możemy je policzyć dzieląc odchylenie standardowe z populacji przez pierwiastek z wielkości próby ($SE = $). Odchylenia standardowego z populacji nie mamy, ale wzór na odchylenie standardowe z próby ma zabezpieczenie, które pozwala użyć odchylenia standardowego z próbki zamiast tego z populacji. Chodzi o tajemnicze dzielenie przez \(N - 1\) zamiast przez \(N\). Dzięki temu zabiegowi możemy szacować błąd standardowy za pomocą tego odchylenia standardowego, które rzeczywiście mamy. To, że coś jest oszacowane3 możemy oznaczyć daszkiem – \(\hat{SE} = \frac{\hat{\sigma}}{\sqrt{N}}\). Czyli odchylenie standardowe rozkładu próbkowania (błąd standardowy) mamy oszacowane, ale średnia takiego zabezpieczenia nie zawiera. Jeśli chcemy wykorzystać średnią z próby zamiast prawdziwej średniej z populacji musimy skorzystać z pewnej sztuczki – zamiast zwykłego rozkładu normalnego wykorzystamy rozkład t.
Rozkład4t to trochę zmodyfikowany rozkład normalny, który bierze pod uwagę fakt, że nie mamy prawdziwej średniej z populacji, tylko obarczoną losowym błędem średnią z próby. Działa on (i wygląda) bardzo podobnie do rozkładu normalnego. Ma też swoją dystrybuantę, z której możemy korzystać identycznie, jak z dystrybuanty rozkładu normalnego. W R dostaniemy się do niej funkcją pt() albo możemy wykorzystać jakiś kalkulator online. Większość kalkulatorów dystrybuanty rozkładu t wymaga jednak wartości wystandaryzowanych, czyli przemielonych wzorem \(Z(x) = \frac{x - M_x}{SD}\).
Do tego, rozkład t, poza średnią i odchyleniem standardowym wykorzystuje jeszcze trzeci parametr – stopnie swobody. Pomyślmy, zadaniem rozkładu t jest wziąć pod uwagę, że nasza średnia z próby ma w sobie jakiś błąd. Ale wydaje się naturalne, że średnia z próby 10 osób pewnie ma większy błąd niż średnia z próby 100 osób. Rozkład t musi więc wiedzieć, jak duża jest nasza próba, żeby określić, jak dużą poprawkę zastosować. Stopnie swobody to złożony matematyczny potworek, który spotkaliśmy już przy wzorze na odchylenie standardowe. Nie będę tłumaczył co to jest i dlaczego, ale żeby dostać liczbę stopni swobody dla rozkładu t, od wielkości naszej próby odejmujemy 1. Próba 100 osób ma więc 99 stopni swobody. W praktyce jest to okienko w kalkulatorze, które trzeba uzupełnić.
Przeróbmy to na przykładzie. Weźmy naszą poprzednią próbkę 100 osób o średniej 10 i odchyleniu standardowym 20. Błąd standardowy wynosi 2 na mocy Centralnego Twierdzenia Granicznego. Załóżmy, że zmierzyliśmy to samo u dzieci karmionych kalarepą i wyszła nam średnia 12. Jaka jest szansa, że to przypadek? Rozwiązywaliśmy już takie problemy za pomocą rozkładu normalnego, teraz jednak robimy to porządnie i wykorzystujemy rozkład t. Chcemy sprawdzić prawdopodobieństwo przypadkowego uzyskania średniej 12 lub więcej. Najpierw standaryzuję nasz wynik 12 i wychodzi \(t = \frac{12 - 10}{2} = 1\). Liczba stopni swobody to \(100 - 1 = 99\). Następnie liczę \(\int^\infty_1 t(x;\ 99) dx\). W R załatwi to komenda pt(1, 99, lower.tail = FALSE) albo 1 - pt(1, 99). Uzyskana wartość to \(p = 15,99\%\), czyli odrobinę wyższa niż ta z rozkładu normalnego. To zawyżenie prawdopodobieństwa to właśnie poprawka na fakt, że nie mamy średniej z populacji, tylko z próby. Jak widać różnica nie jest duża, a to wynika z faktu, że jeśli nasza próbka to jakieś 100 lub więcej osób, to rozkłady t stają się naprawdę bardzo podobne do rozkładów normalnych.
AdnotacjaTest t-Studenta
Policz błąd standardowy.
Wystandaryzuj różnicę. Załóż, że prawdziwa jest średnia grupy kontrolnej.
Policz liczbę stopni swobody \(N-1\).
Policz wartość dystrybuanty rozkładu t:
\(\int_{-\infty}^{x} t(x;\ df) dx\) – dla hipotezy kierunkowej zakładającej spadek.
\(\int^{\infty}_{x} t(x;\ df) dx\) – dla hipotezy kierunkowej zakładającej wzrost.
\(1 - \int_{-x}^{x} t(x;\ df) dx\) albo inaczej \(\int_{-\infty}^{-x} t(x;\ df) dx + 1 - \int_{x}^{\infty} t(x;\ df) dx\) – dla hipotezy bezkierunkowej.
W rzeczywistości jest kilka rzeczy, które można zrobić lepiej, żeby odpowiedzieć na to pytanie. Związane jest to z tym, jak się modeluje różnice. Jeśli średnia dzieci karmionych kalarepą się różni, ale odchylenie standardowe jest takie samo, to możemy policzyć to tak, jak pokazałem wyżej. Nazywa się to testem t Studenta. Jeśli jednak nie zakładamy, że odchylenia standardowe tych dwóch populacji (ogólnej i dzieci karmionych kalarepą) są identyczne, powinniśmy dodać wariancje tych dwóch rozkładów, żeby uzyskać wariancję rozkładu próbkowania różnicy. Innymi słowy tworzymy tutaj trzeci rozkład, który nie pokazuje nam średniej w populacji ogólnej, ani średniej w populacji dzieci karmionych kalarepą, ale mówi nam, jakie różnice między próbkami z tych dwóch populacji będziemy spotykać. Różnica tutaj wyniosła 2 (na plusie). Rozkład ten może nam powiedzieć, jak łatwo dostać różnicę 2 przez przypadek albo innymi słowy jak często będziemy spotykali taką lub większą różnicę. Tutaj i dzieci karmione standardowo, i dzieci karmione kalarepą wykazały błąd standardowy 2. Wariancja to odchylenie standardowe do kwadratu, więc \(2^2 + 2^2 = 8\). Jeśli chcemy mieć znowu błąd standardowy (ale tym razem różnicy, nie żadnej średniej), wyciągamy z tego pierwiastek \(\sqrt{8} = 2 \sqrt{2} \approx 2,83\). Różnicę 2 dzielimy więc przez nowo uzyskane odchylenie \(\frac{2}{2,83} = 0,71\). I dopiero tę wartość wrzucamy do dystrybuanty \(p = 1 - pt(0.71,\ 99) \approx 24\%\). W takiej wersji (niezakładającej różnych wariancji) ten test nazywa się testem t Welcha. W R jest to domyślny test t, przeprowadzany jeśli nie ustawimy tego inaczej.
AdnotacjaTest t-Welcha
Policz osobno błędy standardowe w obu grupach.
Podnieś je do kwadratu, żeby uzyskać wariancje i zsumuj je.
Wyciągnij z otrzymanej wariancji pierwiastek, żeby uzyskać błąd standardowy rozkładu różnic.
Wystandaryzuj różnicę. Załóż, że prawdziwa jest średnia grupy kontrolnej. Wykorzystaj błąd standardowy rozkładu różnic.
Policz liczbę stopni swobody \(N-1\).
Policz wartość dystrybuanty rozkładu t:
\(\int_{-\infty}^{x} t(x;\ df) dx\) – dla hipotezy kierunkowej zakładającej spadek.
\(\int^{\infty}_{x} t(x;\ df) dx\) – dla hipotezy kierunkowej zakładającej wzrost.
\(1 - \int_{-x}^{x} t(x;\ df) dx\) albo inaczej \(\int_{-\infty}^{-x} t(x;\ df) dx + 1 - \int_{x}^{\infty} t(x;\ df) dx\) – dla hipotezy bezkierunkowej.
WskazówkaZadanie
Załóżmy, że badamy, jak soplówka jeżowata (taki grzyb) wpływa na funkcje poznawcze. Wykorzystamy sobie prawdziwe dane z badań Moriego i współpracowników (2009). Zbadaliśmy 2 grupy po 15 osób. Przez 16 tygodni jednej grupie podawaliśmy placebo, a drugiej soplówkę jeżowatą. Na koniec zmierzyliśmy ich funkcje poznawcze standaryzowanym testem. Po 16 tygodniach, w grupie eksperymentalnej średni wynik w teście funkcji poznawczych wyniósł \(M_{eksp.} = 27,4\) (\(SD_{eksp.} = 1,6\)), zaś w grupie kontrolnej \(M_{kont.} = 25,4\) (\(SD_{kont.} = 4\)). Czy różnica jest istotna statystycznie (czyli czy prawdopodobieństwo uzyskania tego wyniku przypadkowo wynosi mniej niż 5%)?
Policz z założeniem (ewidentnie fałszywym), że grupy mają identyczną wariancję równą wariancji grupy kontrolnej.
Załóż hipotezę kierunkową, że soplówka jeżowata zwiększa skuteczność w testach funkcji poznawczych (różnica taka jaka jest lub wyższa).
Załóż hipotezę bezkierunkową, że soplówka jeżowata zmienia skuteczność w testach funkcji poznawczych (różnica w dół lub w górę).
Policz bez założenia o jednorodności wariancji.
Załóż hipotezę kierunkową.
Załóż hipotezę bezkierunkową.
AdnotacjaOdpowiedź
5.0.1 1.
Najpierw liczę błąd standardowy: \[
SE = \frac{4}{\sqrt{15}} = 1,03
\]
Potem standaryzuję różnicę zakładając, że średnia z grupy kontrolnej jest prawdziwa: \[
t = \frac{27,4 - 25,4}{1,03} = 1,94
\]
5.0.1.1 1.1
Liczę wartość \(p\) dla hipotezy kierunkowej: \[
\int_{1,94}^{\infty} t(x;\ 14) dx = 1 - pt(1.94,\ 14) \approx 3,6\%
\]
3,6% to mniej niż 5%, a więc różnica jest istotna statystycznie.
9,3% to więcej niż 5%, czyli różnica jest nieistotna statystycznie.
6 Podsumowanie
Rozkład zmiennej w próbie mówi nam tylko o danej konkretnej próbie. Rozkład próbkowania mówi nam, jak wyglądają średnie we wszystkich możliwych próbach i jak łatwo jest je uzyskać.
Jak mówi Centralne Twierdzenie Graniczne, rozkład próbkowania jest normalny, jeśli próba liczy minimum 15 (według niektórych 30) obserwacji. Średnia tego rozkładu równa jest prawdziwej średniej z populacji.
Rozkład próbkowania ma swoje odchylenie standardowe zwane błędem standardowym, liczone ze wzoru z Centralnego Twierdzenia Granicznego \[SE = \frac{\sigma}{\sqrt{N}}\]
Z tego wzoru wynika, że im większa próba, tym błąd standardowy mniejszy, a więc średnia z próby bardziej wiarygodna.
Wzór na odchylenie standardowe ma w sobie poprawkę, która pozwala używać go zamiast odchylenia standardowego z populacji. Jeśli chcemy użyć średniej z próby jako średniej z populacji, musimy wykorzystać rozkład t.
Istotność statystyczną, gdy wariancje są równe, możemy sprawdzić testem t-Studenta. Wartość t do dystrybuanty liczymy ze wzoru \[t = \frac{x - M}{SE}\]
Istotność statystyczną, bez założenia jednorodności wariancji, możemy sprawdzić testem t-Welcha. Wartość t do dystrybuanty liczymy ze wzoru \[t = \frac{x - M}{\sqrt{SE_1^2 + SE_2^2}} = \frac{x - M}{\sqrt{\frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2}}}\]
Bibliografia
Borch-Jacobsen, M. (2021). Freud’s patients: a book of lives. London: Reaktion Books.
Mori, K., Inatomi, S., Ouchi, K., Azumi, Y., & Tuchida, T. (2009). Improving effects of the mushroom Yamabushitake ( Hericium erinaceus ) on mild cognitive impairment: a double-blind placebo-controlled clinical trial. Phytotherapy Research, 23(3), 367–372. https://doi.org/10.1002/ptr.2634
Wackerly, D. D., Mendenhall, W., & Scheaffer, R. L. (2008). Mathematical statistics with applications (Seventh edition). Belmont: Thomson Brooks/Cole.
Przypisy
Sprawa jest nieco bardziej skomplikowana. Prawdą jest, że odpowiednio duża próbka wystarczy, żeby uznać, że rozkład próbkowania jest normalny, ale może on być normalny też dla mniejszych prób, jeśli rozkład zmiennej też jest normalny. I tak na przykład próbka 10 wyników w teście inteligencji też będzie miała normalny rozkład próbkowania, bo inteligencja rozkłada się normalnie. Ale w praktyce badań naukowych takie rozważania to bicie piany – nikt nie będzie robił badania ilościowego z próbką 10 osób. Jedyny moment, kiedy może się to przydać, to gdy niezbyt duża próbka zostanie jeszcze podzielona na podgrupy i okaże się np. że mężczyzn jest mniej niż 15 (w badaniach psychologicznych nierzadkie zjawisko!). Uzyskanie istotności statystycznej z taką próbką i tak będzie trudne, ale założenie normalności rozkładu próbkowania nie zostanie złamane.↩︎
A dokładnie wynosi \(\int_{101}^\infty \mathcal N(x;\ 100,\ 0,47) \approx 1,7\%\), jeśli chcemy znać szansę uzyskania średniej 101 lub większej albo \(3,3\%\), jeśli nie zakładamy, w którą stronę mężczyźni różnią się od kobiet i liczymy w obie strony.↩︎
W rzeczywistości rozkłady t to cała grupa nieco różniących się od siebie w szczegółach rozkładów, z których najbardziej znany jest rozkład t-Studenta. Student to pseudonim Williama S. Gosseta, który opracował ten rozkład, żeby móc testować partie piwa Guinness. Gosset chciał, żeby różnice między piwem wzorcowym a każdą partią wypuszczaną na rynek nie były istotne statystycznie.↩︎