Znajdź i zmień to narzędzie ostateczne
Oszczędzanie czasu z wyrażeniami regularnymi
Wyrażenia regularne to specjalny szyfr czy kod służący sprawnemu znajdowaniu fragmentów o określonej strukturze w istniejącym tekście. Jeśli chcesz przeczytać o generowaniu całkiem nowego tekstu, sprawdź ten wpis.
Jak wiele razy dawałem wyraz na tej stronie – nie znoszę mechanicznej pracy. To pożeracz czasu, który nic nie wnosi do naszego życia, a uszczupla je systematycznie. Zwłaszcza irytujące są te zadania, co do których czujemy, że polegają na dokładnie tym samym za każdym razem. Intuicyjnie nawet możemy czuć, że muszą istnieć sposoby, żeby tę pracę wykonać automatycznie.
1 Możliwości
Zwlekałem z napisaniem tego tekstu, bo ciężko mi było znaleźć uniwersalny przykład zastosowania wyrażeń regularnych w praktyce. Wszystkie wydają się bardzo konkretne, wąskie. Bałem się, że osoba czytająca ten przykład może pomyśleć „nie zdarzyło mi się to”. I takie w istocie są wyrażenia regularne, ale trochę o to w nich chodzi – żeby zastosować je konkretnie do własnych potrzeb, które mogą być bardzo specyficzne. Jednak ogólne możliwości są bardzo duże, a paleta zastosowań nieskończona. Bardzo prostym przykładem jest sytuacja, gdy otrzymaliśmy listę elementów ponumerowanych tekstem (w sensie nie jest to lista w Wordzie, tylko numerki są rzeczywiście zapisane). Z różnych przyczyn możemy chcieć się tych numerków pozbyć. Czasem musiałem to robić jak składałem tekst. Załóżmy, że mamy taką listę:
Keter
Chochma
Bina
Chesed
Gewura
Tiferet
Necach
Hod
Jesod
Malchut
Możemy zaznaczyć każdy numerek i wykonać tę nudną, mechaniczną pracę. Ale im więcej elementów na liście, tym zmarnuje nam to więcej czasu. Gdybyśmy mogli powiedzieć komputerowi „na początku każdego wersu jest liczba, kropka i spacja – usuń je”, oszczędziłoby nam to czas. I tutaj właśnie przychodzą nam w sukurs wyrażenia regularne. Jest to zestaw kodów pozwalających nam zapisać takie rzeczy jak „początek wiersza” (^) i „jedna lub więcej dowolna liczba” (\d+), dzięki czemu możemy jednym kliknięciem usunąć nasze liczby w całym tekście.
Jako drugi, bardziej złożony przykład wezmę swoją specyficzną potrzebę. Ostatnio poprawiałem linki do innych wpisów na tym blogu. Wcześniej używałem linków do stron, które wyglądały tak:
Więcej można przeczytać w tekście o [podstawach R](https://nieobliczalne.pl/posts/podstawy_R.html).
Jak doczytałem potem, mogłem użyć lepszej składni, która idzie tak:
Więcej można przeczytać w tekście o [podstawach R](./posts/podstawy_R.qmd).
Ma ona kilka zalet, m.in. to, że jakbym kiedykolwiek zmienił domenę, to nie muszę poprawiać wszystkich linków ręcznie. Zdecydowałem się więc poprawić starą konwencję na nową. Poprawianie linków we wszystkich wpisach to jednak dużo mechanicznej pracy, której nie lubię. Narzędziem, które mogłoby się tutaj przydać, jest zwykłe znajdź i zmień (find & replace). Możemy zwrócić uwagę, że wystarczy, abym https://nieobliczalne.pl zamienił na kropkę, a końcowe html na qmd. Nie mogę jednak tego zrobić na raty, bo wtedy zamienię też html z innych linków na qmd.
Wyrażenia regularne pozwalają mi zakodować swoje potrzeby. Potrzebuję wyszukać wszystkie słowa zapisane wielką literą? Nie ma problemu. Potrzebuję zamienić w długim kodzie wyrażenia typu {AUT.15} na {AUT_15}, gdzie liczby są różne? Spoko. Chcę masowo zmienić spacje po jednoliterowych myślnikach na twarde spacje? Jasne. Potrzebuję spacjami podzielić wszystkie numery telefonów w tekście na trójki? Da się zrobić. Chcę wyszukać dane słowo we wszystkich formach (paczka, paczki, paczce itd.)? Potrzymaj mi herbatę. O ile nasz tekst ma określoną strukturę, możemy go wyszukać i w razie potrzeby zmodyfikować.
2 Gdzie korzystać?
Zanim dojdziemy do tego, jak stosować wyrażenia regularne, powiedzmy sobie, gdzie możemy je stosować. Po pierwsze ma je wiele edytorów tekstu (Notepad++, Kate i inne), ale niewiele pakietów biurowych. Możemy je znaleźć w Google Docs i LibreOffice. Microsoft Office ma własny, beznadziejny system „znaków wieloznacznych” (wildcards), tak jakby nie mogli zastosować ogólnoświatowego standardu. Każde IDE programistyczne, wliczając RStudio i VS Code, daje możliwość używania RegEx. W programowaniu przydają się one szczególnie.
Mamy też wiele wygodnych stron, na których możemy testować (i wykorzystywać) wyrażenia regularne, a które podpowiedzą nam różne popularne znaki lub zbiory i wyjaśnią, co robi to, co napisaliśmy. Kluczowe przykłady to RegEx101 i RegExr. Z nich polecam korzystać zwłaszcza na początku. Przykłady w tym wpisie to screeny z RegEx101.
W ramach samego języka programowania również zazwyczaj możemy korzystać z wyrażeń regularnych. W R obsługuje je głównie pakiet stringr, zaś w Pythonie odpowiada za nie biblioteka re. Pozwolą one np. na masową modyfikację ciągów znaków w bazach danych.
Oryginalnie wyrażenia regularne związane są z programem grep i powiązanego z nim sed, a także języka awk i jego uwspółcześnionej wersji gawk. grep to wyszukiwarka tekstu w pliku, sed służy głównie do zamiany fragmentów tekstu, zaś awk to cały język stworzony specjalnie do manipulacji tekstem. Wszystkie one niezmiennie są dostępne w linuksie jako programy działające w konsoli.
3 Zbiory znaków i |
Załóżmy, że chcemy znaleźć różne formy słowa „statystyka”. Odmieniając to słowo przez przypadki otrzymujemy ten sam rdzeń statysty- i końcówki -ka, ki, -ce itd. Zostańmy przy liczbie pojedynczej. Za przykład wykorzystajmy sobie tekst:
Statystyka to nauka, która zajmuje się zbieraniem, analizą i interpretacją danych liczbowych. Jej podstawowym celem jest odkrywanie regularności i wzorców w zjawiskach społecznych, ekonomicznych, naukowych i innych dziedzinach. W statystyce można zastosować wiele różnych metod, takich jak testy hipotez, analiza regresji, czy wykorzystanie rozkładów prawdopodobieństwa. Bez statystyki trudno byłoby dokonać rzetelnych prognoz czy wykazać zależności między zjawiskami. Dlatego statystykę można lubić lub nie, ale ciągle jest ona ważna. Statystyko! Dziękujemy ci!
Wyrażenia regularne pozwalają nam powiedzieć „wszystko, co ma rdzeń statystyk- i dane końcówki”. W tym wypadku wykorzystamy operator lub zapisywany znakiem separatora | (klawisz tuż pod backspace, klikany z shiftem) oraz nawiasy kwadratowe, które tworzą zbiory znaków (character sets).
[Ss]tatysty(ka|ki|ce|kę|ką|ko)
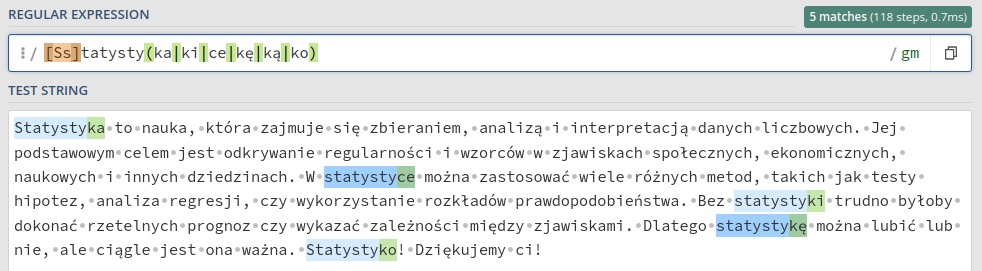
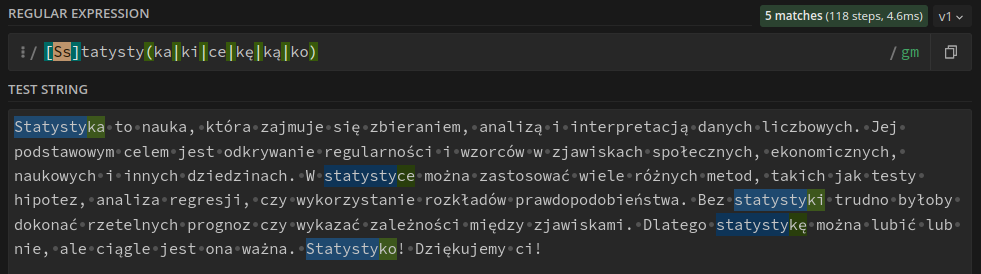
Rozbijmy ten przykład na czynniki pierwsze. Po pierwsze mamy [Ss]. Nawiasy kwadratowe oznaczają, że wyrażenie ma wyszukiwać jeden ze znaków wewnątrz nich. W tym wypadku dopasuje zarówno duże, jak i małe S. Mogę tam też zapisywać przedziały typu [0-9] albo [A-Za-z]. Możemy też powiedzieć „wszystko poza znakami ze zbioru”, co zrobimy pisząc ^, np. [^0-9] dopasuje wszystko, co nie jest cyfrą.
Dalej mamy zwykłą część słowa „statystyka” i nawiasy. RegEx domyślnie ignoruje nawiasy (tj. nie wyszukuje ich). Służą one jako znaki specjalne do tworzenia grup, o których więcej później. Wewnątrz nawiasu wypisałem końcówki, które mają być dopasowane. Każdą końcówkę rozdzieliłem pionową kreską, co oznacza „albo to, albo to, albo to…“.
Jeśli chcielibyśmy wyszukać rzeczywiste nawiasy albo separator „|“, musimy poprzedzić je lewym ukośnikiem \. Ta czynność nazywa się escaping i wymagają tego wszystkie znaki specjalne, na czele z nawiasami, kropką i samym lewym ukośnikiem, który wyszukujemy pisząc \\. Później będzie o tym więcej, ale chodzi o to, że jak chcemy wyszukać znak (, to w wyrażeniu regularnym zapiszemy \(, bo samo ( oznacza początek grupy. Lewy ukośnik przełącza specjalne znaczenie na dosłowne.
Poprzedni przykład mógłbym napisać nieco zwięźlej jako [Ss]tatysty[kc][aieęąo]. Technicznie wtedy dopasujemy też takie twory jak „statystycą” albo „statystyke”, ale to zazwyczaj nie jest problem, bo ich w tekście po prostu nie ma. Tutaj pojawia się jednak dość ważny wniosek – wyrażenia regularne dość łatwo się pisze i fatalnie się czyta.
Jako ciekawostkę mogę podać, że pisząc to wyrażenie regularne odmieniłem słowo „statystyka” przez przypadki w Kate, potem wyrażeniami regularnymi usunąłem „statysty-“, zastąpiłem znak nowej linii (\n) separatorem (|) i na koniec ręcznie wziąłem to w nawiasy (patrz tutaj). Tak było mi łatwiej, niż pisać same te końcówki. Ale ja jestem uczulony na pracę mechaniczną bardziej niż reszta społeczeństwa i robiłem to już tyle razy, że nawet o tym nie myślę. Tak jest mi szybciej, ale nie każdy potrzebuje robić takie rzeczy automatycznie.
4 Znaki specjalne i kotwice
RegEx dysponuje całą serią znaków specjalnych typu „dowolna liczba” (\d), „dowolna litera” (\w), „dowolny znak odstępu” (\s, głównie spacja, ale też np. tabulator albo twarde spacje) itd. Najszerszym znaczeniowo znakiem tego typu jest kropka (.). Oznacza ona po prostu „dowolny znak”. Dokładny spis tych znaków specjalnych może różnić się w zależności od wersji (flavour) RegEx, jaką dany program czy język implementuje. Są to wygodne skróty dla zapisów typu [0-9]. Każdy z nich ma też wersję zanegowaną w postaci wielkiej litery, np. \D dopasuje wszystko, co nie jest liczbą. Do tego dochodzą nam znaki niewidoczne typu znak nowej linii (\n, „enter”) albo tabulator (\t).
Jeśli podajemy dane wyrażenie regularne jako argument w jakiejś funkcji w języku programowania, bardzo często będziemy musieli zapisać np. \\d czy \\n. Wynika to z faktu, że język programowania musi wiedzieć, że chodzi nam o lewy ukośnik w wyrażeniu regularnym, a nie, że escape’ujemy jakiś znak. Innymi słowy jeśli w Pythonie czy w R zapiszemy po prostu "\d", to program zwariuje, bo nie będzie wiedział, jak escape’ować literę d. Dlatego zapiszemy "\\d" i wtedy program odczytując coś takiego, zrozumie to jako \d. Jednak znowu – to się tyczy tylko języków programowania.
RegEx implementuje również tak zwane kotwice, czyli oznaczenia pozycji. Mówiąc konkretnie, ^ oznacza początek linii (akapitu), a $ oznacza koniec linii. linia jest tutaj fragmentem tekstu między kolejnymi „enterami”, a nie tym, co akurat program wyświetla jako linię tekstu. Dlatego w tekście ciągłym cały akapit jest, technicznie, linią.
Weźmy sobie za przykład tekst skopiowany z Worda, w którym mamy pozostałości po listach, które chcemy usunąć. Chodzi nam o sekwencje liczba, kropka i spacja obecne na początku linijki tekstu.
Wariancja – co to jest wariancja, jak się ją wyjaśnia i co to jest model.
Testy statystyczne i wartość p – jak działają testy statystyczne, co to jest p i jak je interpretować.
Kombinatoryka – krótkie omówienie podstawowych terminów kombinatoryki, może być 1. wprowadzeniem do prawdopodobieństwa.
Odpowiednie wyrażenie regularne mogłoby brzmieć ^\d\.. Po kropce jest tam spacja, którą silnik uporczywie mi usuwa, dlatego na stronie jej nie widać.
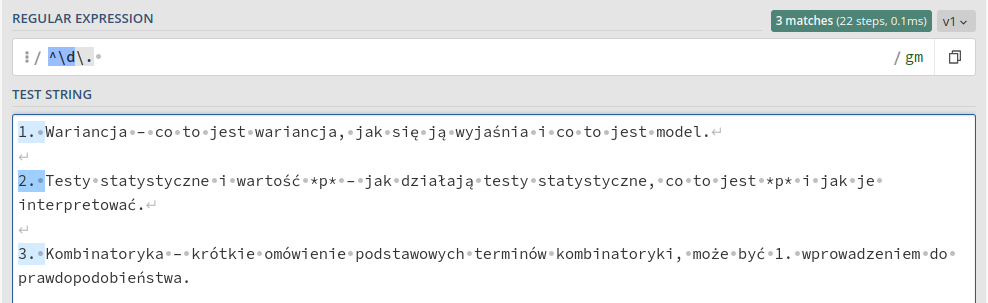
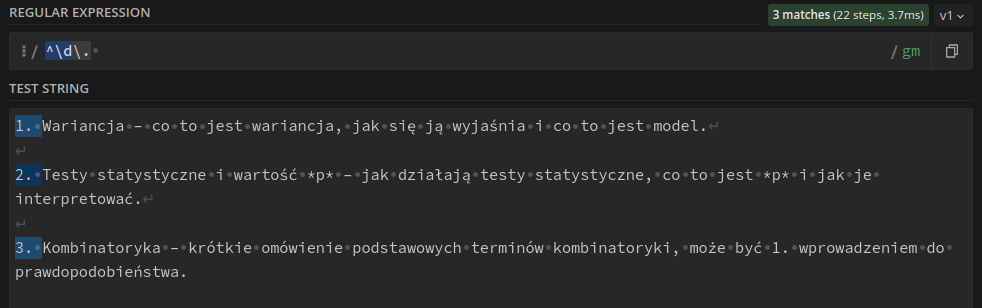
Zwróćmy uwagę na kilka rzeczy. Po pierwsze, to wyrażenie nie dopasowało liczby „1.” w treści 3. punktu. Wynika to z tego, że dodaliśmy ^ na początku wyrażenia. Liczby, które nie są na początku linijki nie są przez to dopasowywane. Po drugie, musiałem przed kropką dodać ukośnik. Wynika to z faktu, że kropka to znak specjalny (oznacza dowolny znak) i jeśli chcemy wyszukać dosłowną kropkę, musimy wykorzystać lewy ukośnik.
5 Powtarzanie
Najbardziej (według mnie) użyteczne operatory, jakie oferuje RegEx, to operatory powtarzania. Jest to seria operatorów mogących powiedzieć „jedna lub więcej cyfr” albo „zero lub więcej liter”. Możemy wykorzystać je np. do znalezienia wszystkich tekstów wewnątrz nawiasów albo wszystkich słów zaczynających się wielką literą. Spróbujmy zrobić to drugie.
Teoretycznie tyle wystarczy, ale żeby uprzyjemnić proces pisania, fajnie jest przygotować sobie jakieś IDE (program do programowania), np. Visual Studio Code albo chociaż porządny edytor tekstu w stylu Notepad++.
[A-Z]\w+
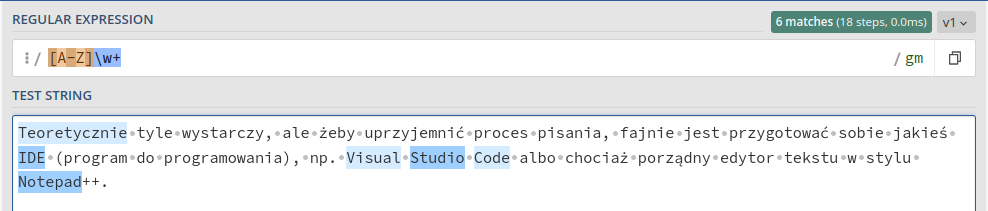
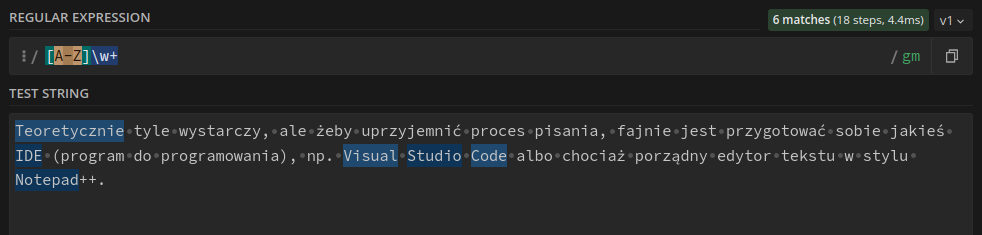
Znak + oznacza tutaj „jeden lub więcej”, a więc \w+ oznacza „jedna litera lub więcej”. Operatorów podobnych do + jest więcej i możemy je zobaczyć w tabelce.
| Operator | Znaczenie |
|---|---|
? |
zero lub jedno wystąpienie |
* |
zero lub więcej wystąpień |
+ |
jedno lub więcej wystąpień |
{n} |
dokładnie n wystąpień |
{n,} |
n lub więcej wystąpień |
{n,m} |
między n a m wystąpień |
Z użyciem tych operatorów może się wiązać problem chciwości (greedyness). Załóżmy, że tym razem chcemy wyszukać wszystko, co zostało zapisane w nawiasach1.
Dlaczego jednak napisałem range(1, 11) a nie range(1, 10)? Python działa tutaj specyficznie. Wynika to z faktu, że w informatyce liczy się od 0, nie od 1. Jeśli do funkcji range() wrzucę tylko jedną liczbę, czyli na przykład range(10), to dostanę 10 elementów. Ponieważ jednak pierwszy element to 0, to będą to liczby od 0 do 9. Mogę podać dwie liczby, żeby powiedzieć funkcji range(), od czego ma zacząć, ale wtedy muszę mieć w głowie, że skoro range(0, 10) oznacza 10 liczb od 0 do 9, to liczby od 1 do 10 muszę zapisać jako range(1, 11). Innymi słowy koniec skali nie wlicza się do zakresu.
\(.+\)
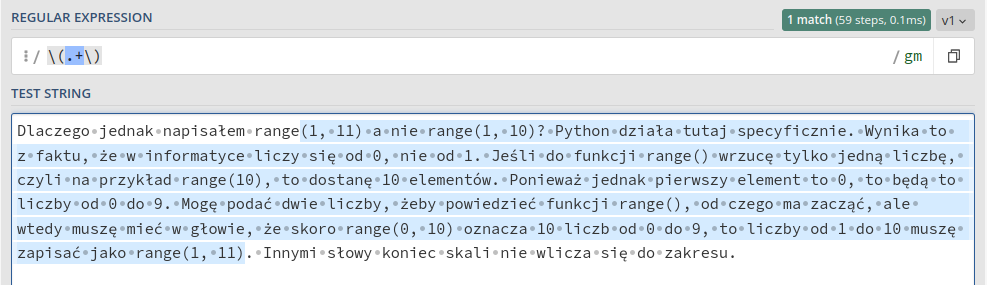
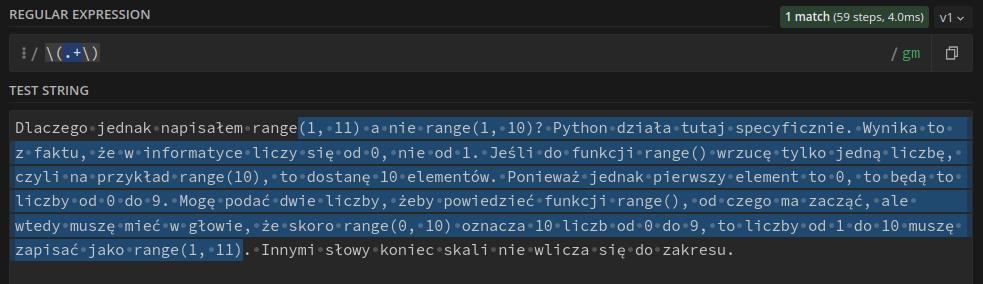
Dziwne. Czemu takie długie wyszło? W naszym wyrażeniu regularnym wykorzystałem nawiasy (z lewym ukośnikiem, bo nawiasy to znak specjalny) oraz sekwencję .+ oznaczającą „jeden dowolny znak lub więcej”. Domyślnie jednak + jest chciwy (greedy) i wyszuka najdłuższe możliwe sekwencje. Oznacza to, że zaznaczył wszystko między pierwszym nawiasem otwierającym i ostatnim nawiasem zamykającym. W końcu nawiasy zamykające łapią się do kategorii dowolnych znaków. Żeby temu przeciwdziałać, zamiast .+ możemy użyć .+?.
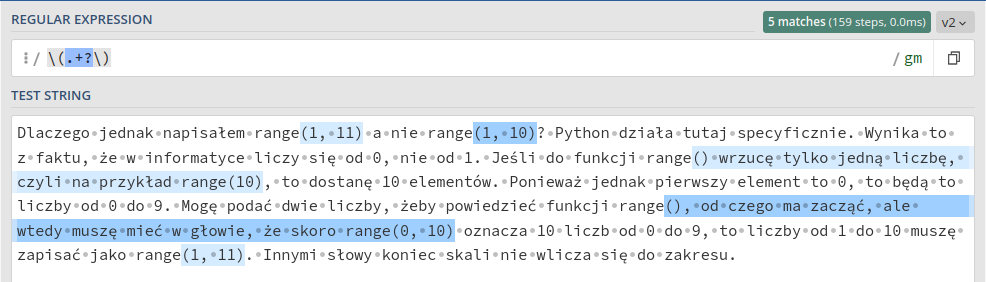
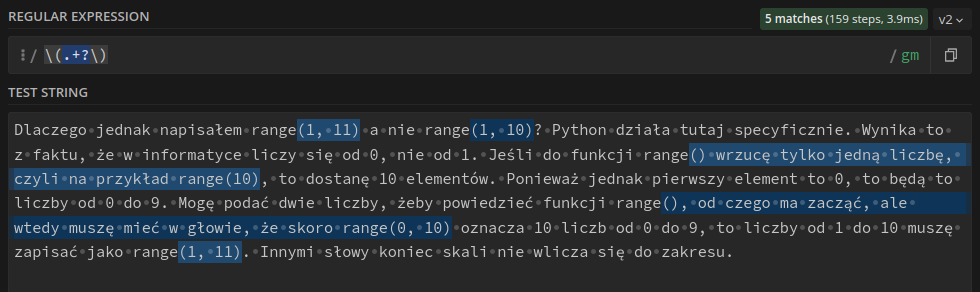
Jest już lepiej! Problem jednak powodują w tym wypadku puste nawiasy. Nasze wyrażenie regularne wymaga, by między nawiasami coś było. Takie właśnie sekwencje znajduje w przypadku zapisu (). Nawias zamykający jest po prosu kolejnym znakiem, czyli łapie się jako ., a dopasowanie kończy dopiero kolejny nawias zamykający.
Rozwiązania widzę tutaj dwa. Po pierwsze można wykorzystać lookarounds, żeby pustych nawiasów nie dopasowywać. Pozwolą one też dopasować tekst wewnątrz nawiasów bez samych nawiasów. Nie chcę jednak wchodzić tak głęboko, dlatego zainteresowanych odsyłam tutaj. Po drugie możemy umożliwić dopasowywanie też pustych nawiasów zastępując operator „jeden lub więcej” (+) operatorem „zero lub więcej” (*). Pamiętajmy jednak o chciwości tych operatorów i dodajmy jeszcze ?.
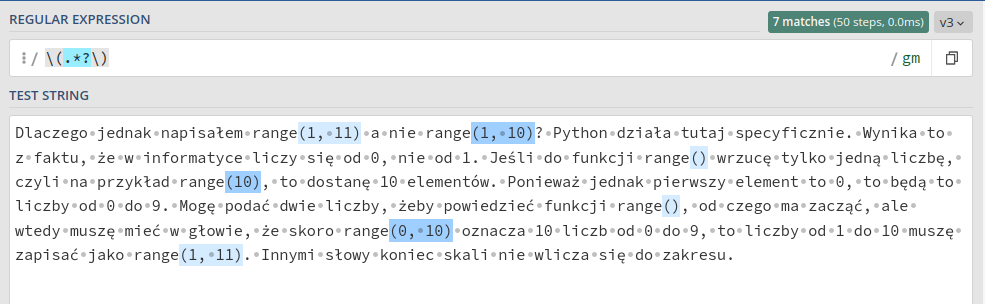
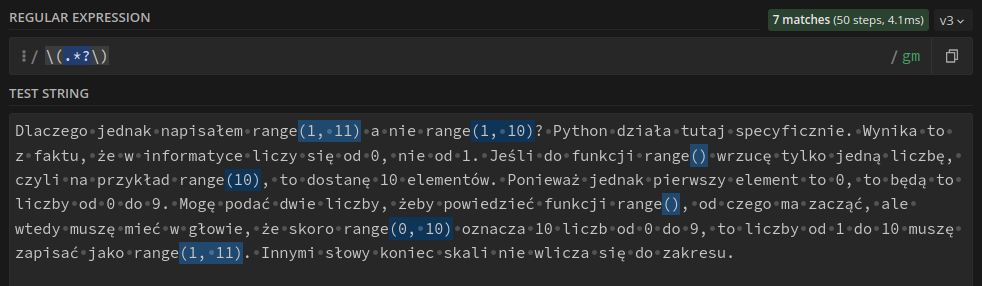
6 Grupy i zastępowanie
Zazwyczaj po to wyszukujemy tekst, żeby zastąpić go innym. Jak to jednak zrobić, jeśli mamy takie fragmenty tekstu jak .+? Nie mogę wpisać w pole z tekstem do podstawienia .+, bo dostanę dosłowną kropkę i plus. Program musi dokładnie wiedzieć, co w dane miejsce wstawić. Załóżmy, że w poprzednim przykładzie chcemy zamienić nawiasy okrągłe na kwadratowe. Jak to zrobić? Za pomocą grup.
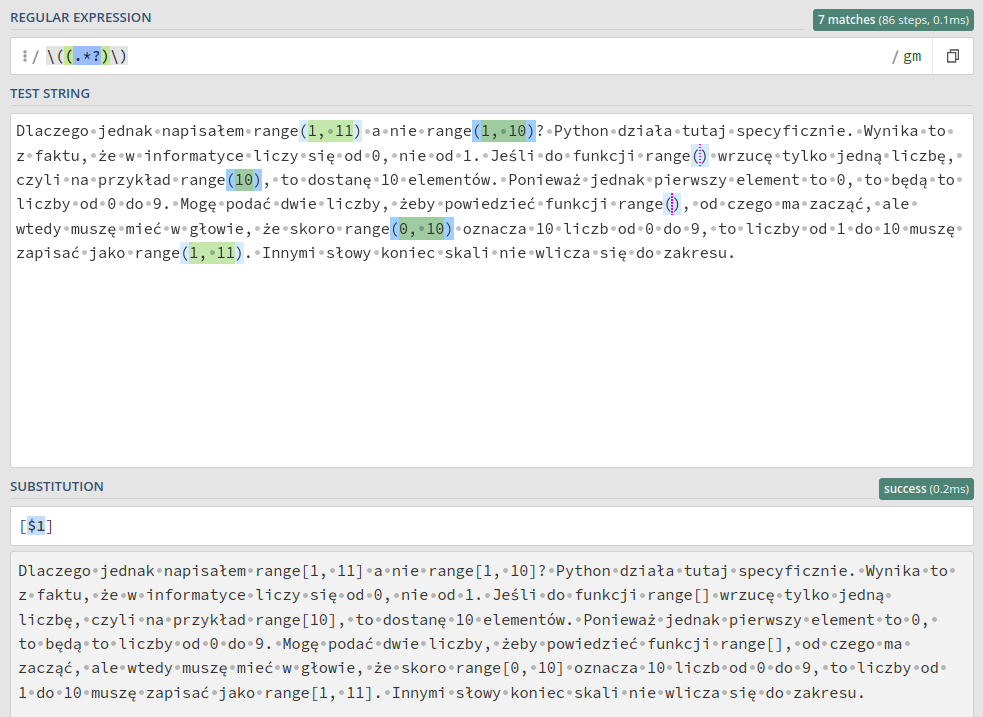
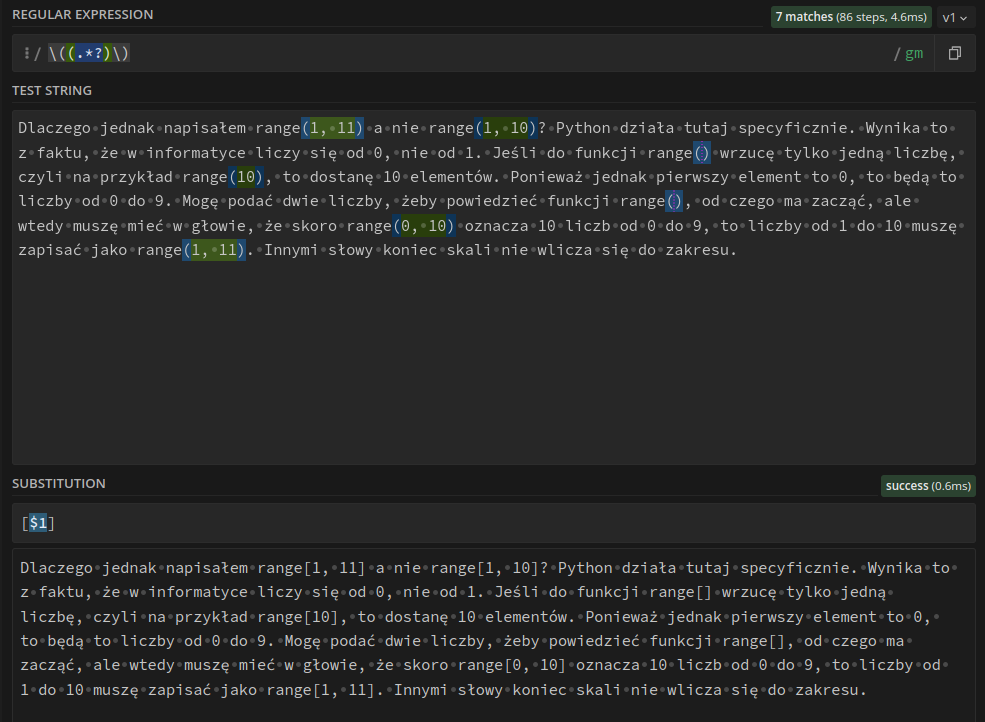
Jak to zrobiłem? Najpierw w wyszukiwaniu zmieniłem sekwencję \(.*?\) w \((.*?)\). Innymi słowy otoczyłem .*? dodatkową parą nawiasów. Na screenie zaznaczone są na zielono. Znaki w nawiasach tworzą grupy. Grupy po to są nam potrzebne, żebyśmy mogli je potem wykorzystywać do zastępowania tekstu2. Zwróćmy uwagę na tekst w drugim polu, gdzie wpisałem [$1]. Oznacza to „tekst z pierwszej grupy ($1) w nawiasach kwadratowych”. Czyli bierzemy wnętrze naszego pierwotnego nawiasu (grupę 1.) i otaczamy je nawiasami kwadratowymi. Nawiasy okrągłe nie są częścią grupy, więc nie pojawiają się w tekście po zmianie.
Odwołania do grup mogą wyglądać różnie w różnych wersjach RegEx. W tym wypadku użyłem $1, ale możemy się też spotkać z innymi oznaczeniami, przede wszystkim \1. Zależy to od programu.
7 Zamiana linków na ścieżki
Z całą tą nową wiedzą możemy wreszcie rozwiązać problem z początku tego wpisu. Przypomnijmy – chcemy linki zamienić na ścieżki do plików .qmd.
Więcej można przeczytać w tekście o [podstawach R](https://nieobliczalne.pl/posts/podstawy_R.html).
Rozwiązaniem, którego ja użyłem, było:
]\(.+(posts\/.+)\.html\)
Tekstem zastępującym było:
](./$1.qmd)
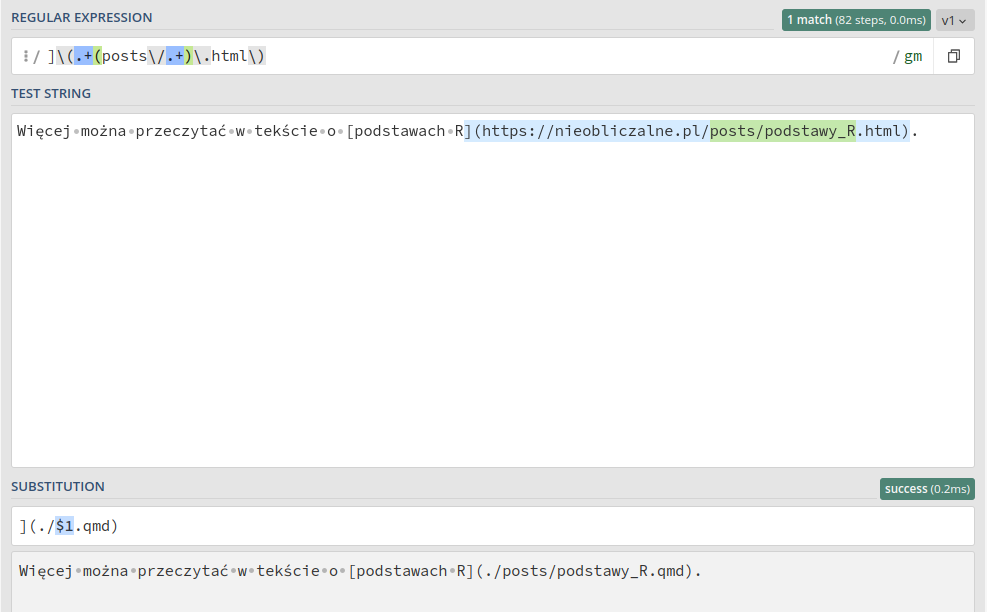

Zaczynam zamykającym nawiasem kwadratowym, bo hiperlinki w markdown są formatowane jako [tekst](link). Dalej otwieram dosłowny nawias okrągły i w nim dowolny tekst. Mogłem napisać dokładny link, bo to o ten i żaden inny tekst mi chodzi, ale nie chciało mi się pisać. Zabezpieczyłem się przed złymi dopasowaniami słowem „posts”. Po nim znajduje się prawy ukośnik i dowolne znaki, czyli wewnętrzna nazwa danego wpisu. posts/.+ jest też grupą, dlatego jest w nawiasach. Wyrażenie zakończone jest rozszerzeniem .html i nawiasem zamykającym. Całość zastępuję swoją grupą posts/nazwa_wpisu poprzedzoną tekstem ./3 i zakończoną rozszerzeniem .qmd. Całość otaczam odpowiednimi nawiasami.
Czy mogłem zrobić to lepiej? Oczywiście! Tylko po co? Te sekwencje muszą być użytkowe. Nie musimy się starać, żeby były odporne na błędy i działały w każdym wypadku. To są rzeczy, które pisze się szybko, wykorzystuje i kasuje. Nie muszą być idealne, muszą być napisane sprawnie i działać tu i teraz, w tym konkretnym przypadku. W końcu po to uczymy się wyrażeń regularnych, żeby oszczędzić sobie pracy, a nie jej przysporzyć. Jeśli robimy coś często i chcemy to zachować na przyszłość, to może wtedy warto się bawić w szlifowanie. Podobnie jeśli wyrażenie regularne jest częścią skryptu. Mimo wszystko w większości przypadków piszemy wyrażenia regularne na jeden raz i warto o tym pamiętać.
8 Ściągi
Informacji jest dużo, ale na szczęście nie musimy tego wszystkiego znać na pamięć, żeby z tego korzystać. Możemy się wspierać różnymi dostępnymi w sieci materiałami, które przypomną nam, jak się coś robiło. Kluczowe jest, by wiedzieć, że coś da się zrobić. Chyba najlepszym materiałem, z którego korzystam praktycznie zawsze, jak chcę napisać wyrażenie regularne, jest cheat sheet do pakietu stringr, który możemy znaleźć tutaj. Mam go w szufladzie biurka położonego tak, że jest to pierwsze, co widzę, jak ją otworzę. Jeśli zapomnę, jak było „zero albo więcej” albo chcę zrobić coś bardziej skomplikowanego, to patrzę do szuflady i już pamiętam. Rzeczy, których używam często, zdążyłem zapamiętać, a resztę czytam ze ściągi.
9 Bonus: szybkie usuwanie sierot
Zanim zacznie się kontrowersja, „sieroty” oznaczają tutaj wiszące jednoliterowe spójniki, które nie powinny znaleźć się na końcu linijki. Pozbywamy się ich za pomocą twardych spacji. Zazwyczaj scrollujemy dokument w Wordzie i wyszukujemy je wzrokiem, po czym dodajemy gdzie trzeba. Potem zmieniamy wielkość czcionki albo szerokość akapitu i wszystko się rozjeżdża. Wyrażeniami regularnymi możemy dodać spacje nierozdzielające wszędzie za jednym zamachem. Jak wspominałem, Word nie obsługuje wyrażeń regularnych, więc musimy to zrobić w Libre Office. Trzeba tylko w okienku Znajdź i zamień, w Innych opcjach zaznaczyć Wyrażenia regularne. Nie będę tutaj tłumaczył jak to działa, podam gotowy przepis.
Wyszukaj to:
(?<=\s)([wuioaz])\sZamień na to:
$1 Zwrócę tylko uwagę, że po $1 musi być twarda spacja. Możemy ją dodać klikają na pole tekstowe prawym przyciskiem myszy, wchodząc w znaki specjalne i wyszukując NO-BREAK SPACE. Ma ona kod 160 (U+A0).
10 Podsumowanie
Na koniec mogę polecić dwa źródła informacji o wyrażeniach regularnych. Pierwsza to strona RexEgg, która zawiera mnóstwo wpisów uszeregowanych w tutoriale od podstaw do czarnego pasa. Druga to książka Wyrażenia regularne autorstwa Jeffreya Friedla, wydana nakładem Wydawnictwa Helion. Oba źródła są pełne informacji, sztuczek i gotowych rozwiązań, za pomocą których różne czary można czynić w tekście. Na stronie RegexOne znajdziemy również interaktywne ćwiczenia.
Wyrażenia regularne (regular expressions, RegEx) pozwalają znajdować i modyfikować regularne struktury w tekście.
Nawiasy kwadratowe dopasowują dowolny znak zapisany w tych nawiasach, np.
[tk]dopasuje statystyka.[^tk]dopasuje odwrotność, czyli statystyka.^to początek linijki,$to koniec linijki.Istnieje cała seria znaków wieloznacznych, z których najważniejsze to
\w(dowolna litera),\d(dowolna cyfra),\s(dowolny znak typu spacja),.(dowolny znak) i\n(znak nowej linii, „enter”).Operatory ilości pozwalają powiedzieć, że dany znak pojawia się więcej niż raz –
*(zero lub więcej),+(jeden lub więcej),?(zero lub jeden). Domyślnie te operatory są chciwe (greedy), a żeby to zmienić, dodajemy do nich znak zapytania –*?i+?.Grupy bierzemy w nawiasy. Potem możemy wykorzystywać te grupy w zastępowaniu, pisząc
$1lub\1w zależności od systemu.Wyrażenia regularne to coś, co piszemy na szybko, na już, żeby działało tu i teraz, a niekoniecznie, żeby działało zawsze.
Dobrą ściągą jest cheat sheet do pakietu
stringr.
Przypisy
W rzeczywistości RegEx ma do tego specjalne operatory, ale nie chcę wchodzić tak głęboko.↩︎
Ewentualnie możemy ich użyć do stosowania operatorów do całych grup, np.
(foo)+dopasuje jedno całe słowo „foo” lub ich więcej. Bez nawiasu+odnosiłby się tylko do litery „o”.↩︎Warto zauważyć, że w polu, w którym wpisujemy tekst, którym zastępujemy nasze dopasowania, nie musimy już escape’ować znaków specjalnych. Tam już wszystkie znaki są dosłowne.↩︎